El Data Analysis se ha consolidado como el pilar fundamental de la toma de decisiones en la era digital moderna. En un mundo saturado de información, la capacidad de transformar datos brutos en conocimiento estratégico es lo que diferencia a las empresas exitosas de las que se quedan atrás. Python, gracias a su versatilidad y potencia, se ha convertido en el lenguaje predilecto para ejecutar estos procesos de análisis con una precisión quirúrgica.
Dominar el Data Analysis permite a los profesionales explorar patrones ocultos, predecir tendencias de mercado y optimizar operaciones complejas de manera automatizada. No se trata solo de manejar números, sino de contar historias coherentes que guíen el rumbo de una organización. La curva de aprendizaje de Python facilita que perfiles de diversas áreas puedan sumergirse en este ecosistema tecnológico sin necesidad de ser ingenieros de software experimentados.
La relevancia del Data Analysis trasciende los sectores tecnológicos, impactando la medicina, las finanzas, el marketing y hasta la logística global. Al utilizar bibliotecas especializadas, los analistas pueden limpiar grandes volúmenes de datos, realizar cálculos estadísticos avanzados y generar visualizaciones impactantes. Esta disciplina es el corazón de la ciencia de datos y el motor que impulsa la inteligencia artificial contemporánea.
Adoptar un enfoque basado en datos requiere disciplina, curiosidad y el manejo de herramientas adecuadas para el Data Analysis. A lo largo de este recorrido, exploraremos cómo Python facilita cada etapa del flujo de trabajo, desde la adquisición de la información hasta la comunicación de resultados. Entender estas dinámicas es esencial para cualquier persona que aspire a liderar proyectos innovadores en el mercado laboral actual.
La importancia del Data Analysis en el entorno actual
En la actualidad, el Data Analysis no es una opción, sino una necesidad competitiva para sobrevivir en mercados altamente volátiles. Las organizaciones generan terabytes de información diariamente, pero esos datos por sí solos carecen de valor si no se someten a un proceso riguroso de interpretación. Python ofrece un entorno robusto donde la manipulación de estructuras de datos complejas se vuelve una tarea eficiente y reproducible.
El valor del Data Analysis reside en su capacidad para reducir la incertidumbre en entornos empresariales críticos. Al aplicar modelos analíticos, es posible identificar ineficiencias en los procesos internos y descubrir nuevas oportunidades de ingresos que antes eran invisibles. Esta capacidad de diagnóstico convierte al analista en un activo estratégico indispensable para cualquier junta directiva o equipo de desarrollo de producto.
Además, el Data Analysis fomenta una cultura de objetividad dentro de las empresas, sustituyendo las corazonadas por evidencia empírica. Cuando las decisiones se respaldan con datos, el margen de error disminuye drásticamente y la transparencia aumenta. Python facilita esta transición cultural al permitir que los análisis sean auditables, escalables y fáciles de compartir entre diferentes departamentos.
Bibliotecas esenciales para el Data Analysis con Python
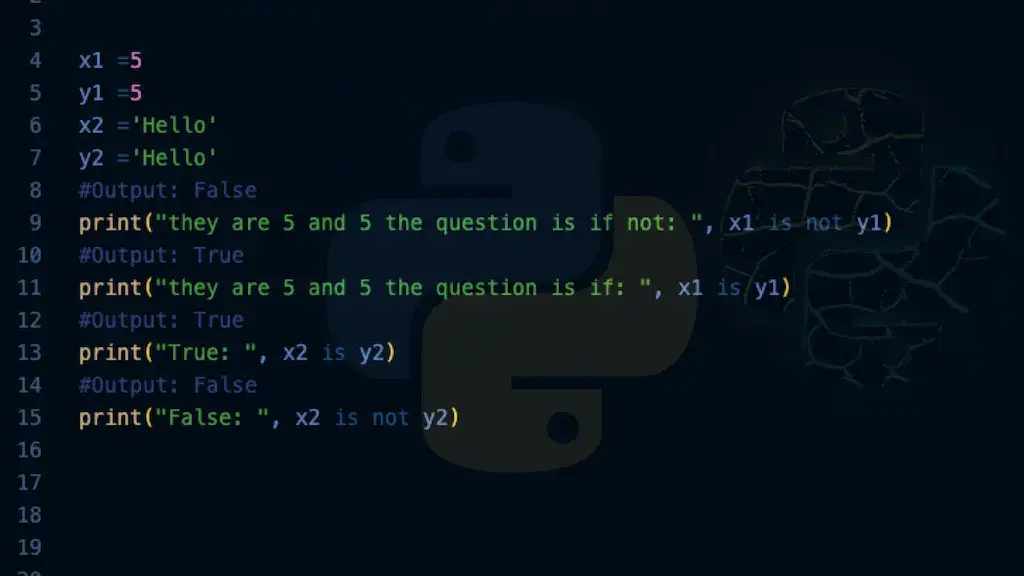
Para realizar un Data Analysis de alto nivel, es imprescindible conocer las bibliotecas que componen el ecosistema científico de Python. Pandas es, sin duda, la herramienta más utilizada para la manipulación y el análisis de datos estructurados mediante sus famosos DataFrames. Su capacidad para filtrar, agrupar y fusionar conjuntos de datos es incomparable en términos de rendimiento y sencillez.
Otra pieza clave en el Data Analysis es NumPy, que proporciona soporte para vectores y matrices de grandes dimensiones. Esta biblioteca es fundamental para el cálculo numérico y sirve como base para muchas otras herramientas del ecosistema. Sin la eficiencia computacional que aporta NumPy, el procesamiento de grandes volúmenes de información sería significativamente más lento y costoso en términos de recursos.
La visualización es otra etapa crítica del Data Analysis, y para ello contamos con Matplotlib y Seaborn. Estas librerías permiten convertir filas de datos abstractos en gráficos intuitivos que facilitan la comprensión de tendencias y anomalías. Una buena visualización puede comunicar en segundos lo que un informe de cien páginas no lograría transmitir con la misma claridad a los interesados.
El proceso de limpieza en el Data Analysis
Uno de los mayores retos en el Data Analysis es la limpieza de datos, también conocida como data wrangling. Los datos del mundo real suelen ser caóticos, contienen valores nulos, duplicados o formatos inconsistentes que pueden sesgar los resultados finales. Dedicar tiempo a sanear la información es vital para garantizar que las conclusiones obtenidas sean precisas y confiables.
Durante el Data Analysis, la fase de limpieza consume a menudo el 80% del tiempo total del proyecto. Python simplifica esta tarea mediante funciones integradas que permiten detectar y tratar valores faltantes de forma automática. Es fundamental establecer protocolos claros de limpieza para asegurar la integridad de la base de datos antes de proceder a cualquier tipo de modelado estadístico.
Ignorar la calidad de los datos en el Data Analysis conduce a resultados erróneos, un fenómeno conocido como «garbage in, garbage out». Por ello, los expertos en la materia enfatizan la importancia de validar cada fuente de información y normalizar las variables. Un dataset limpio no solo mejora la precisión de los modelos, sino que también facilita la colaboración entre diferentes equipos técnicos.
Análisis exploratorio de datos (EDA)
El Análisis Exploratorio de Datos, o EDA por sus siglas en inglés, es una etapa crucial en el Data Analysis que busca entender la estructura del dataset. A través de técnicas estadísticas descriptivas, el analista identifica la distribución de las variables y las relaciones de correlación entre ellas. Este paso es fundamental para generar hipótesis válidas que luego serán probadas mediante modelos más complejos.
En el Data Analysis, el EDA permite detectar valores atípicos (outliers) que podrían representar errores de medición o descubrimientos excepcionales. Utilizar diagramas de caja o histogramas ayuda a visualizar la dispersión de los datos y a comprender el comportamiento de la población estudiada. Esta fase es puramente investigativa y requiere una mente analítica capaz de cuestionar la información presentada.
Dominar el EDA dentro del Data Analysis dota al profesional de una visión periférica sobre el problema a resolver. Al identificar patrones visuales, se pueden seleccionar las características más relevantes para alimentar algoritmos de aprendizaje automático. El éxito de cualquier proyecto de ciencia de datos depende en gran medida de la profundidad y el rigor con que se realice este análisis previo.
Estadística aplicada al Data Analysis
La estadística es el lenguaje matemático que sustenta el Data Analysis y permite validar las conclusiones obtenidas. Sin una base estadística sólida, el análisis corre el riesgo de ser una simple descripción de hechos pasados sin capacidad predictiva. Conceptos como la desviación estándar, la p-valor y los intervalos de confianza son herramientas diarias para cualquier analista serio.
En el Data Analysis, el uso de pruebas de hipótesis permite determinar si las diferencias observadas entre grupos son estadísticamente significativas o fruto del azar. Python ofrece módulos como SciPy que automatizan estos cálculos complejos, permitiendo que el analista se concentre en la interpretación de los resultados. La estadística proporciona el marco de rigor necesario para transformar observaciones en leyes de negocio.
Además, el Data Analysis moderno utiliza modelos de regresión para entender cómo una variable afecta a otra en un entorno controlado. Comprender la causalidad frente a la correlación es uno de los mayores desafíos en esta disciplina. Un análisis estadístico bien ejecutado es la mejor defensa contra las interpretaciones erróneas que pueden llevar a decisiones empresariales costosas y equivocadas.
Visualización de datos y Storytelling
El Data Analysis no termina cuando se obtiene el resultado numérico, sino cuando este se comunica de forma efectiva. El storytelling con datos es el arte de presentar hallazgos complejos de una manera que sea comprensible para una audiencia no técnica. Las visualizaciones deben ser limpias, precisas y, sobre todo, orientadas a la acción para que tengan un impacto real.
Dentro del Data Analysis, elegir el gráfico adecuado es tan importante como el cálculo estadístico mismo. Un gráfico de barras puede ser ideal para comparaciones, mientras que un gráfico de líneas es preferible para mostrar la evolución temporal de una métrica. Python permite personalizar cada detalle estético de las gráficas, asegurando que el mensaje central no se pierda entre elementos visuales innecesarios.
La narrativa que acompaña al Data Analysis debe conectar los puntos entre los datos y los objetivos de la organización. Un analista exitoso sabe explicar no solo «qué» está sucediendo, sino también «por qué» y «qué pasos» se deben tomar a continuación. Esta capacidad de síntesis convierte la información técnica en una herramienta poderosa para influir en la dirección estratégica de una compañía.
El futuro del Data Analysis y la Inteligencia Artificial
El campo del Data Analysis está evolucionando rápidamente gracias a la integración con el aprendizaje automático y la inteligencia artificial. Los analistas ya no solo miran hacia el pasado para entender lo que ocurrió, sino que utilizan modelos predictivos para anticipar escenarios futuros. Esta transición hacia el análisis prescriptivo representa la vanguardia de la tecnología actual en el manejo de información.
Python sigue siendo el líder indiscutible en esta evolución, proporcionando bibliotecas como Scikit-learn para implementar algoritmos de predicción dentro del flujo de Data Analysis. La automatización de tareas analíticas permite procesar volúmenes de datos que serían imposibles de manejar manualmente. Estamos entrando en una era donde la capacidad analítica está limitada únicamente por nuestra creatividad y capacidad de procesamiento.
Para mantenerse relevante, es vital seguir aprendiendo sobre las nuevas tendencias que afectan al Data Analysis, como el procesamiento de lenguaje natural y la visión por computador. La educación continua y la práctica constante en plataformas como Pandas Documentation son esenciales para cualquier profesional. El futuro pertenece a quienes sepan extraer valor del caos de información que nos rodea.
Integración de herramientas y automatización
La eficiencia en el Data Analysis aumenta exponencialmente cuando se integran diferentes herramientas de flujo de trabajo. Python se conecta fácilmente con bases de datos SQL, servicios en la nube como AWS o Google Cloud y aplicaciones de visualización como Tableau. Esta interoperabilidad permite construir pipelines de datos automatizados que funcionan en tiempo real sin intervención humana constante.
Automatizar el Data Analysis permite a las empresas reaccionar con mayor rapidez ante cambios inesperados en el mercado. Por ejemplo, un sistema puede analizar automáticamente los sentimientos de los clientes en redes sociales y ajustar las campañas de marketing al instante. La programación en Python es el pegamento que une todas estas tecnologías para crear una infraestructura de datos coherente y resiliente.
Además, el Data Analysis automatizado reduce el riesgo de errores manuales que suelen ocurrir en procesos repetitivos. Al escribir scripts robustos, el analista garantiza que el procesamiento de la información sea consistente cada vez que se ejecute. La inversión inicial en automatización se traduce en un ahorro masivo de tiempo y recursos a largo plazo para cualquier departamento técnico.
Ética y privacidad en el análisis de información
El ejercicio del Data Analysis conlleva una gran responsabilidad ética respecto al manejo de la privacidad de los usuarios. En un entorno regulado por leyes como el GDPR, los analistas deben asegurarse de que la recolección y el procesamiento de datos cumplan con los estándares legales. La transparencia en el uso de la información es fundamental para mantener la confianza del público y de los clientes.
Durante el proceso de Data Analysis, es vital anonimizar los datos sensibles para proteger la identidad de las personas involucradas. El sesgo algorítmico es otro desafío ético importante que puede llevar a decisiones discriminatorias si no se controla adecuadamente. Un buen analista debe ser capaz de identificar y mitigar estos sesgos para garantizar que sus modelos sean justos y equitativos.
La ética en el Data Analysis no es solo un requisito legal, sino un pilar de la integridad profesional. Las empresas que priorizan la privacidad de los datos suelen obtener una ventaja competitiva basada en la lealtad y la reputación. Por tanto, integrar principios éticos desde el diseño de cualquier proyecto de análisis es una práctica recomendada que beneficia a toda la sociedad.
Convertirse en un experto en esta disciplina requiere una combinación de habilidades técnicas, pensamiento crítico y una gran capacidad de comunicación. Al dominar el Data Analysis con Python, abres las puertas a una carrera llena de desafíos intelectuales y oportunidades de crecimiento constante. La clave del éxito radica en la curiosidad perpetua y en la voluntad de explorar los datos con un enfoque riguroso y creativo. Aprender a manejar estructuras de datos, dominar la limpieza de información y aplicar modelos estadísticos avanzados te permitirá transformar cualquier dataset en una mina de oro de conocimientos. La ciencia de datos es un viaje continuo de descubrimiento donde cada línea de código cuenta una historia diferente.
Empieza hoy mismo a construir tus propios proyectos, experimenta con bibliotecas nuevas y nunca dejes de cuestionar los resultados obtenidos. En un mercado laboral que valora la precisión y la visión estratégica, tu capacidad para ejecutar un Data Analysis impecable será tu mayor ventaja competitiva.